ГЛАВА 2 МЕТОДЫ РАСПРЕДЕЛЕННОЙ ОБРАБОТКИ ДАННЫХ. ОСНОВНЫЕ ПОНЯТИЯ.
Среди всех изменений, происшедших в области связанной с научными
исследованиями вычислительной техники, некоторые в особенности повлияли на
изменение функций рабочих станций, а именно:
- рост мощи станций, оснащаемых
все более дружественными человеко-машинными интерфейсами ;
- появление
процессоров, предназначенных для специальных видов обработки данных
(изображения, текста и т.п.);
- расширение возможностей в области хранения
информации;
- появление средств, облегчающих доступ к ресурсам,
распределенным по сети.
Прогресс в этих областях предоставляет новые возможности в том, что касается
управления данными и эффективности обработки данных. После определения того, что
представляет из себя мультипроцессорная и мультимашинная архитектура, мы вводим
основные понятия, на которых строятся возможности применения ресурсов нескольких
машин:
- распределение или разделение;
- возможность взаимодействия;
-
прозрачность;
- модель "клиент-сервер".
2.2. Мультипроцессоры и мультимашины
В данном разделе речь пойдет об аппаратной архитектуре,на базе которой функционируют методы распределенной обработки данных - архитектуре, которую мы называем мультимашинной , чтобы отличить ее от мультипроцессорной архитектуры. Мы увидим, что это отличие не всегда легко заметно, так как технический прогресс ведет к размыванию границ.
В целях увеличения вычислительных возможностей и для достижения большего
параллелизма по сравнению с мультипрограммированием, предлагаемым операционными
системами, на классические монопроцессорные машины с фоннеймановской
архитектурой были установлены дополнительные процессоры. Подобная
мультипроцессорная архитектура появилась в начале 1960 г.г. (Burroughs 6000 в
1963 г., IBM/360-67 в 1966 г., ...), гораздо раньше, чем были разработаны
вычислительные сетеи. Системы, разрабо-анные для мультипроцессорных машин,
называются параллельными операционными системами (Parallel Operating Systems).
Мультипроцессорные машины подразделяются на два семейства:
- жестко
связанные или жестко соединенные мультипроцессоры (tightly coupled), в которых
процессоры связаны через общую память (рис.2.1.);
- слабо связанные или слабо
соединенные мультипроцессоры (loosely coupled), в которых процессоры связаны
через средство связи (как правило, шину), отличное от общей памяти (рис.2.2.).
Необходимо отметить, что эти виды архитектуры могут сочетаться между собой: каждый процессор может обладать локальной памятью и делить с остальными общую память. Кроме того, в настоящее время процессоры обладают одним или двумя уровнями кэширования...
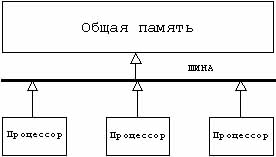
Рис2.1. Жестко
связанные мультипроцессоры
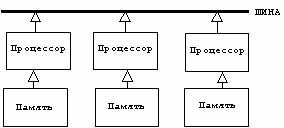
Рис 2.2.Слабо
связанные процессы
Появление сетей, предназначенных для взаимной связи различных компьютеров, привело к разработке средств, а затем и операционных систем, позволяющих осуществлять управление, так называемой, мультимашинной архитектурой (рис.2.3.), то есть совокупности полносоставных компьютеров (процессоры, память, вводы-выводы...), связанных в сеть. В этом случае речь идет о распределенных вычислительных системах.
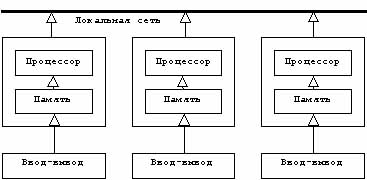
Рис 2.3.Мультимашинная
организация
Следует отметить большое сходство между мультимашинной организацией и
архитектурой слабо связанных мультипроцессоров; в обоих структурах процессоры
связаны через канал связи, а не через общую память. Различия заключаются в
следующем:
- в случае распределенных систем (мультимашинная архитектура)
связь между процессорами осуществляется относительно медленно (сеть), а системы
независимы;
- в случае параллельных систем (мультипроцессорная архитектура)
связь осуществляется быстро (шина), а системы относительно сильно связаны между
собой.
Не существует точного определения этих типов архитектуры и этих систем, кроме того, между этими двумя понятиями наблюдается сходство. Распределенные операционные системы, такие как Mach и Chorus могут применяться как при мультимашинной, так и при мультипроцессорной организации. Впрочем, существует несколько вариантов UNIX для мультипроцессоров (на Cray, на Sun...), в которых сосуществуют совершенно различные средства управления распределением по сети и управления связью между процессорами через шину. В данной книге мы рассматриваем использование средств, преназначенных для применения ресурсов, распределенных между различными машинами, доступ к которым возможен через сеть. Мы не рассматриваем ни средства, направленные исключительно на использование мультипроцессорной архитектуры, ни средства, предназначенные для работы в режиме реального времени, так как целью нашего исследования является совместная работа нескольких машин.
Трудно провести различие между терминами "распределенный", "разделенный" и "совместный".
- данные и обработка являются "распределенными" или "разделенными", то есть, выполнение операции требует использования нескольких процессоров;
- термин "совместный" (cooperatif) является более специфическим: диалог между двумя прикладными системами с целью осуществления некой задачи.
В дальнейшем мы будем использовать все три термина (при этом слово "распределенный" лучше всего передает смысл английского "distributed", откуда и название книги). Возможность взаимодействия определяют как способность систем к совместному использованию данных или к совместной работе с использованием стандартных интерфейсов. Она подразумевает возможность связи между машинами, изготовленными различными фирмами. Возможность взаимодействия подразумевает понятие "открытых систем",то есть систем, способных к коммуникации в неодно- родной среде.
2.4. Что называют распределенной обработкой данных
С точки зрения хронологии, взаимодействие между программами последовательно
приобретало следующие формы:
- обмен: программы различных систем посылают
друг другу сообщения (как правило, файлы);
- разделение: имеется
непосредственный доступ к ресурсам нескольких машин (совместное пользование
файлом, например);
- совместная работа: машины играют в реализации программы
взаимодополняющие роли.
Рассмотрим пример, иллюстрирующий эту эволюцию. Речь пойдет о проектировании
в области механики; традиционный подход заключается в следующем:
-
построение "проволочной модели" (maillage) (графического представления геометрии
физической модели) на рабочей станции;
- перенос на ЭВМ Cray файла модели,
вводящего код вычислений;
- результаты расчетов, выполненных на ЭВМ Cray
переносятся на рабочую станцию и обрабатываются графическим постпроцессором.
Этот способ обладает следующими недостатками:
- обмен данными
производится посредством переноса файлов с одной машины на другую;
-
обработка файлов осуществляется последовательно, в то время как расчеты на ЭВМ
Cray только выиграли бы, если было бы возможно обеспечить взаимодействие с
пользователем, используя графические и эргономические возможности рабочей
станции, а некоторые расчеты, осуществляемые на последней, лучше было бы
выполнить на машине Cray.
Для того, чтобы избавиться от этих неудобств, необходимо перейти от
вышеназванных вариантов решения задач к применению методики совместной работы,
на основе понятия "прозрачности". Пользователь будет видеть только одну машину
(свою станцию) и только одну прикладную программу. Распределенная обработка
данных, таким образом, представляет собой программу, выполнение которой
осуществляется несколькими системами, объединенными в сеть. Как правило,
расчетная часть программы выполняется на мощном процессоре, а визуальное
отображение выводится на рабочей станции с улучшенной эргономичностью.
Разделение опирается на модель "клиент-сервер", к которой мы еще вернемся. Этот
вид обработки данных организуется по принципу треугольника (рис.2.4.):
-
пользователь обладает рабочей станцией;
- решение задач требует обращения к
устройству обработки данных (спецпроцессору, например) и к серверу данных, и все
это прозрачно для пользователя.
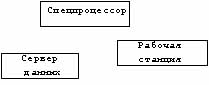
Рис 2.4. Треугольная
организация вычислительного процесса
2.5. Цели распределенной обработки данных
Целью распределенной обработки данных является оптимизация использования ресурсов и упрощение работы пользователя (что может вылиться в усложнение работы разработчика). Каким образом ?
- Оптимизация использования ресурсов.
Термин ресурс, в данном случае используется в самом широком смысле: мощность обработки (процессоры), емкость накопителей (память или диски), графические возможности (2-х или 3-х мерный графический процессор, в сочетании с растровым дисплеем и общей памятью), периферийные устройства вывода на бумажный но- ситель (принтеры, плоттеры). Эти ресурсы редко бывают собраны на одной машине: ЭВМ Cray обладает мощными расчетными возможностями, но не имеет графических возможностей, а также возможностей эффективного управления данными. Отсюда принцип совместной работы различных систем, используя лучшие качества каждой из них, причем пользователь имеет их в распоряжении при выполнении только одной программы.
- Упрощение работы пользователя.
Действительно, распределенная обработка данных позволяет:
- повысить
эффективность посредством распределения данных и видов обработки между машинами,
способными наилучшим образом управлять ими;
- предложить новые возможности,
вытекающие из повышения эффективности;
- повысить удобство пользования.
Пользователю более нет необходимости разбираться в различных системах и
осуществлять перенос файлов.
Основные недостатки этого подхода заключаются в следующем: - зависимость от характеристик и доступности сети. Программа не сможет работать, если сеть повреждена. Если сеть перегружена, эффективность уменьшается, а время реакции систем увеличивается. - проблемы безопасности. При использовании нескольких систем увеличивается риск, так как появляется зависимость от наименее надежной машины сети.
C другой стороны, преимущества весьма ощутимы:
- распределение и
оптимизация использования ресурсов. Это основная причина внедрения
распределенной обработки данных;
- новые функциональные возможности и
повышение эффективности при решении задач;
- гибкость и доступность. В
случае поломки одной из машин, ее пытаются заменить другой, способной выполнять
те же функции.
2.6. Распределение и параллелизм
Следует отметить, что распределение (или разделение) не яв- ляется синонимом параллелизма. Распределение видов обработки состоит в том, чтобы поручить их машинам, наилучшим образом приспособленным к этому. Параллелизм подразумевает понятие одновременности обработки. Распределение позволяет иногда проводить параллельную обработку. Мы вернемся к этому в следующих главах при рассмотрении средств обработки данных.
Прозрачностью называется возможность доступа к ресурсам или услугам, не зная
их местонахождения. С точки зрения прикладного программиста, речь идет о возмож-
ности использования одинаковых примитивов доступа, независимо от местонахождения
службы или необходимого ресурса. У пользователя имеется только один прикладной
интерфейс и он видит перед собой только один компьютер. С более концептуальной
точки зрения, прозрачность определяется как возможность видеть систему как
единый организм, а не как собрание независимых друг от друга объектов. Различают
несколько разновидностей прозрачности, в частности:
- прозрачность доступа: к
локальным или удаленным объектам можно обращаться посредством одинаковых
операций;
- прозрачность местонахождения: объекты должны быть доступны без
необходимости знать их физическое местоположение;
- прозрачность
одновременности доступа: несколько пользователей должны иметь возможность
одновременного доступа к данным, без нежелательных последствий;
-
прозрачность копирования: должна существовать возможность копировать данные из
файлов или из других объектов в целях повышения эффективности или обеспечения
доступности незаметно для пользователей;
- прозрачность при неисправностях:
пользователи или прикладные программы должны иметь возможность завершить свои
задания, даже в случае неисправностей аппаратной или программной части;
-
прозрачность при динамических изменениях конфигурации: система может динамически
менять свою конфигурацию, в целях повышения эффективности и в зависимости от
нагрузки.
Клиентом называется объект,запрашивающий доступ к службе или ресурсу. Сервер - это объект несущий службу или обладающий ресурсом.
Клиент и сервер могут находиться на одной и той же машине (использование локальных механизмов коммуникации) или на двух разных машинах (использование сетевых средств). В рамках нашего исследования, клиентом и сервером являются два процесса UNIX, связанные между собой через механизм IPC (Interprocess Communication), локальный или сетевой (рис.2.5.).
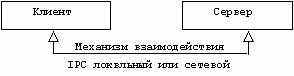
Рис2.5. Модель
клиент-сервер
Клиент и сервер не играют симметричную роль. Процесс-сервер инициализируется и, затем, переходит в состояние ожидания запросов от возможных клиентов. Как правило, процесс-клиент запускается в интерактивном режиме и посылает запросы серверу. Сервер исполняет полученный запрос, причем это может подразумевать диалог с клиентом, а может и нет. Затем сервер вновь переходит в состояние ожидания других клиентов.
Различают два типа процессов-серверов:
- итеративные серверы:
процесс-сервер сам обрабатывает ответ. Этот тип сервера используется в случае,
если время обработки весьма непродолжительно или если сервер используется
единственным клиентом.
- параллельные серверы: процесс-сервер вызывает для
обработки вызова клиента другой процесс . Этот процесс создается системным
вызовом fork (). Порождающий процесс не блокируется по окончании выполнения
порожденного процесса и может, таким образом, ждать другие запросы.
С каждым сервером связан служебный (сервисный) адрес. Клиент посылает запросы по этому адресу. В зависимости от вида осуществляемой обработки данных, раз- личают серверы без состояния (stateless) и серверы с состоянием (statefull). Сервер без состояния не сохраняет о своих клиентах никакой информации. Сервер с состоянием сохраняет информацию о состоянии своих клиентов после каждого запроса. В случае разрыва связи, повторный запуск проще у серверов без состояния, но иногда это может привести к случайным срабатываниям.
Речь идет о средствах, предлагаемых средой TCP/IP (в ожидании появления
средств OSI). На рис.2.6. показаны эти средства в архитектуре TСP/IP. В
дальнейшем в данной работе анализируются:
- библиотека сокетов глава 4;
-
библиотека TLI (Transport Level Interface) глава 5;
- NFS (Network File
System) глава 6;
- RFS (Remote File Sharing) глава 7;
- X Window глава
8;
- XDR (eXternal Data Representation) глава 9;
- RPC (Remote Procedure
Call) фирмы Sun глава 10;
- NCS (Network Computing System) глава 11.
Целью распределенной обработки данных является выполнение обработки наиболее
приспособленным для этого процессором. Распределение не подразумевает
параллелизма, но возможность "распараллелить" распределенную обработку
существует. Мы ввели основные понятия, о которых в дальнейшем будет рассказано
более подробно:
- распределенная, или разделенная, или совместно выполняемая
программа: выполнение программы двумя и более машинами, объединенными в
сеть;
- пользователю безразлично местоположение различных ресурсов,
необходимых для успешного выполнения программы, которую он выполняет со своего
рабочего места;
- модель "клиент-сервер" (initiator-responder по терминологии
OSI): клиентом является процесс, запрашивающий услуги у сервера, причем этот
второй процесс может находиться на том же компьютере, а может и нет.
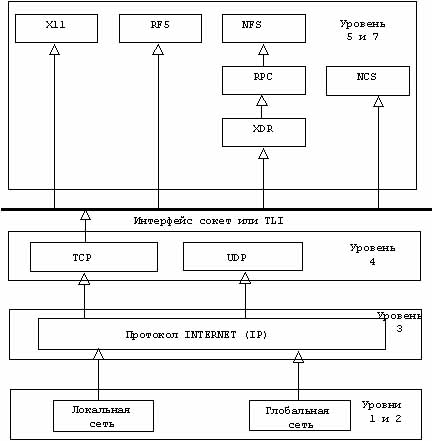
Интерфейссокет или
TLI:интерфейс выше TCP или UDP
XDR:представление данных
RPC,NCS: вызов
удаленных процедур
NFS,RFS:управление распределением файлов
X11:работа с
окнами
Рис 2.6. Средства и услуги TCP